목차
Abstract
I Introduction
II Large Language Models
III HOW LLMS ARE BUILT
IV. HOW LLMS ARE USED AND AUGMENTED
V. POPULAR DATASETS FOR LLMS
VI. PROMINENT LLMS’ PERFORMANCE ON BENCHMARKS
VII. CHALLENGES AND FUTURE DIRECTIONS
Abstract
대형 언어 모델(LLMs)은 2022년 11월 ChatGPT 출시 이후, 다양한 자연어 작업에서 강력한 성능을 보여주며 많은 주목을 받았다. LLM의 범용 언어 이해 및 생성 능력은 대규모 텍스트 데이터를 바탕으로 수십억 개의 모델 파라미터를 훈련시켜 획득되었으며, 이는 스케일링 법칙(scaling laws)으로 예측된 바 있다[1], [2]. LLM 연구 분야는 매우 최근에 시작되었지만, 다양한 방식으로 빠르게 진화하고 있다. 본 논문에서는 GPT, LLaMA, PaLM을 포함한 주요 LLM 계열을 검토하며, 이들의 특성, 기여, 한계점을 논의한다. 또한 LLM 구축 및 향상을 위해 개발된 기술들을 개괄하고, LLM 훈련, 미세 조정 및 평가를 위해 준비된 주요 데이터셋을 조사한다. 아울러 널리 사용되는 LLM 평가 지표를 검토하고, 대표적인 벤치마크에서 여러 인기 있는 LLM의 성능을 비교한다. 마지막으로, 본 논문의 결론에서는 LLM 연구에서의 개방형 과제와 미래 연구 방향에 대해 논의한다.
1 Introduction
언어 모델링은 1950년대 샤논(Shannon)이 정보 이론을 인간 언어에 적용하여 단순한 n-그램 언어 모델이 자연어 텍스트를 얼마나 잘 예측하거나 압축하는지 측정한 연구에 뿌리를 둔 오랜 연구 주제이다[3]. 그 이후로, 통계적 언어 모델링은 음성 인식, 기계 번역, 정보 검색 등 다양한 자연어 이해 및 생성 작업의 기본 요소가 되었다[4], [5], [6].
최근 웹 스케일 텍스트 말뭉치를 사전 학습한 트랜스포머 기반 대형 언어 모델(LLM)의 발전은 언어 모델(LLM)의 능력을 크게 확장시켰다. 예를 들어, OpenAI의 ChatGPT와 GPT-4는 자연어 처리뿐만 아니라 복잡한 새로운 작업을 수행하기 위한 다단계 추론을 수행하며, 사람의 지시를 따를 수 있는 일반 작업 해결사로 Microsoft의 Co-Pilot 시스템에 동력을 제공하는 데 사용될 수 있다. 따라서 LLM은 범용 AI 에이전트 또는 인공지능 일반 지능(AGI) 개발을 위한 기본 빌딩 블록이 되고 있다.
LLM 연구 분야는 매우 빠르게 발전하고 있으며, 몇 개월 또는 몇 주 만에 새로운 발견, 모델 및 기술이 발표되고 있다[7], [8], [9], [10], [11]. 이에 따라 AI 연구자와 실무자들은 자신들의 작업을 위한 LLM 기반 AI 시스템을 구축하기 위한 최적의 방식을 찾는 데 어려움을 느끼고 있다. 본 논문은 LLM의 최근 발전에 대한 시의적절한 설문 연구를 제공하며, 학생, 연구자 및 개발자들에게 유용하고 접근 가능한 자료가 되기를 희망한다.
LLM(대형 언어 모델)은 신경망을 기반으로 한 대규모 사전 학습된 통계 언어 모델이다. LLM의 최근 성공은 수십 년간의 언어 모델 연구와 개발의 축적 결과이며, 이는 시작점과 발전 속도가 다른 네 가지 물결로 구분할 수 있다: 통계 언어 모델(SLM), 신경 언어 모델(NLM), 사전 학습 언어 모델(PLM), 그리고 대형 언어 모델(LLM)이다.
통계 언어 모델(SLM)
SLM은 단어의 조건부 확률을 추정하여 텍스트의 확률을 단어 확률의 곱으로 계산하는 방식이다. SLM의 주요 형태는 마르코프 연쇄 모델인 n-그램 모델로, 이전 n−1개의 단어를 기반으로 현재 단어의 확률을 계산한다. 단어 확률은 텍스트 말뭉치에서 수집된 단어와 n-그램 빈도를 사용하여 추정되므로, 데이터 희소성(즉, 이전에 본 적 없는 단어나 n-그램에 대해 확률을 0으로 할당하는 문제)을 다루기 위해 스무딩 기법을 사용한다. 스무딩은 모델에서 일부 확률 질량을 본 적 없는 n-그램을 위해 예약하는 방법이다[12]. n-그램 모델은 많은 NLP 시스템에서 널리 사용되지만, 데이터 희소성으로 인해 자연어의 다양성과 변화를 완전히 포착하지 못해 불완전하다는 한계를 가진다.
초기 신경 언어 모델(NLM)
초기 NLM[13], [14], [15], [16]은 단어를 저차원의 연속 벡터(임베딩 벡터)로 매핑하여 데이터 희소성을 해결하고, 신경망을 통해 이전 단어의 임베딩 벡터를 집계하여 다음 단어를 예측한다. NLM이 학습한 임베딩 벡터는 숨겨진 공간(hidden space)을 정의하며, 이 공간에서 벡터 간의 거리를 통해 의미적 유사성을 쉽게 계산할 수 있다. 이는 입력 형식에 상관없이 의미적 유사성을 계산할 수 있는 가능성을 열어준다(예: 웹 검색에서의 쿼리와 문서[17], [18], 다른 언어로 된 문장[19], [20], 이미지 캡션 작업에서의 이미지와 텍스트[21], [22]). 초기 NLM은 특정 작업에 맞춰 학습된 작업 전용 모델로, 작업별 데이터로 학습되며 학습된 숨겨진 공간 역시 작업 전용이다.
사전 학습 언어 모델(PLM)
PLM은 초기 NLM과 달리 작업에 구애받지 않는다. 이러한 일반성은 학습된 숨겨진 임베딩 공간에도 적용된다. PLM의 학습 및 추론 과정은 사전 학습과 미세 조정(pre-training과 fine-tuning) 패러다임을 따른다. 순환 신경망[23] 또는 트랜스포머[24], [25], [26]을 활용한 언어 모델이 웹 스케일의 라벨 없는 텍스트 말뭉치를 사용해 단어 예측과 같은 일반 작업을 위해 사전 학습되고, 소량의 작업별 라벨 데이터로 특정 작업에 맞게 미세 조정된다. 최근 PLM에 대한 설문 연구로는 [8], [27], [28]이 있다.
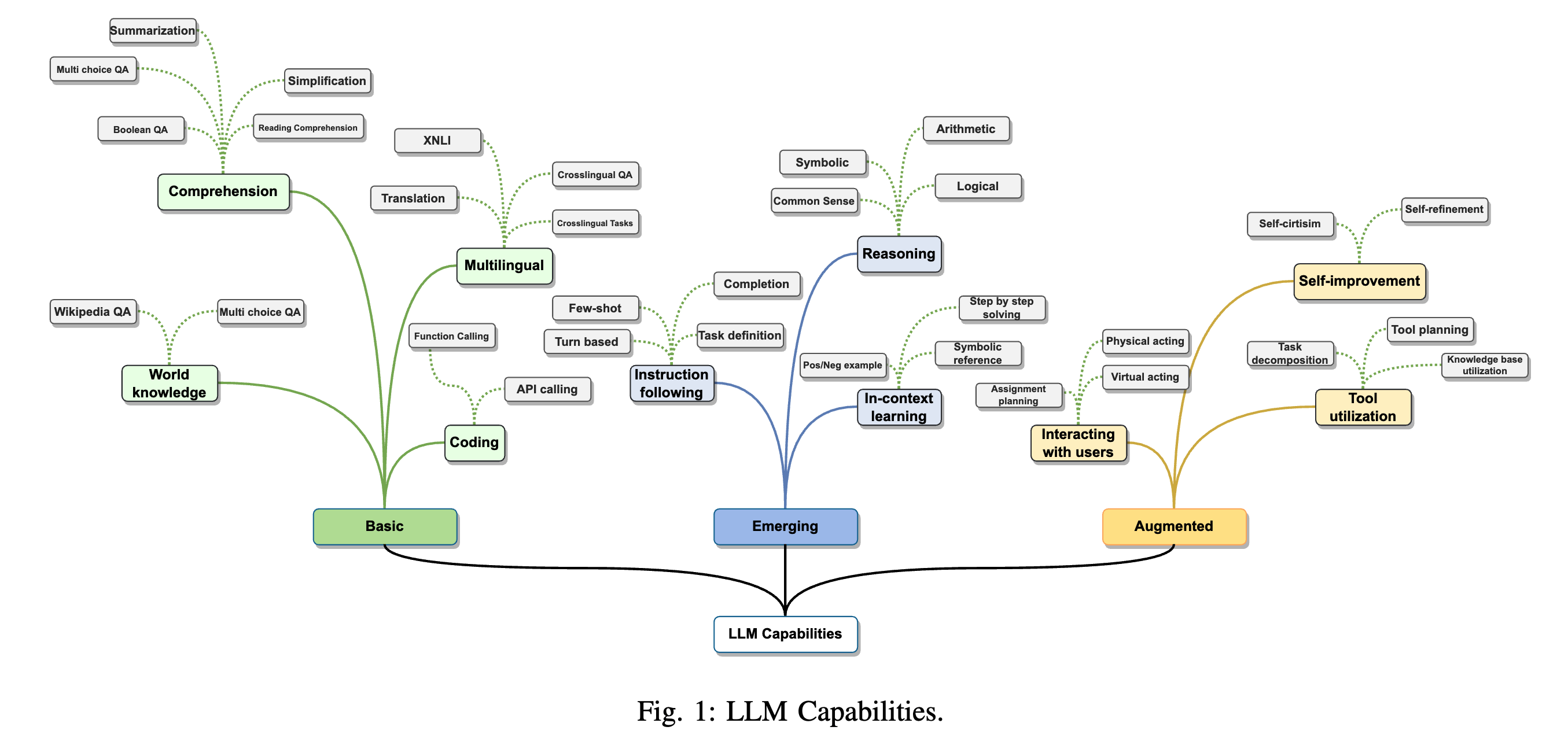
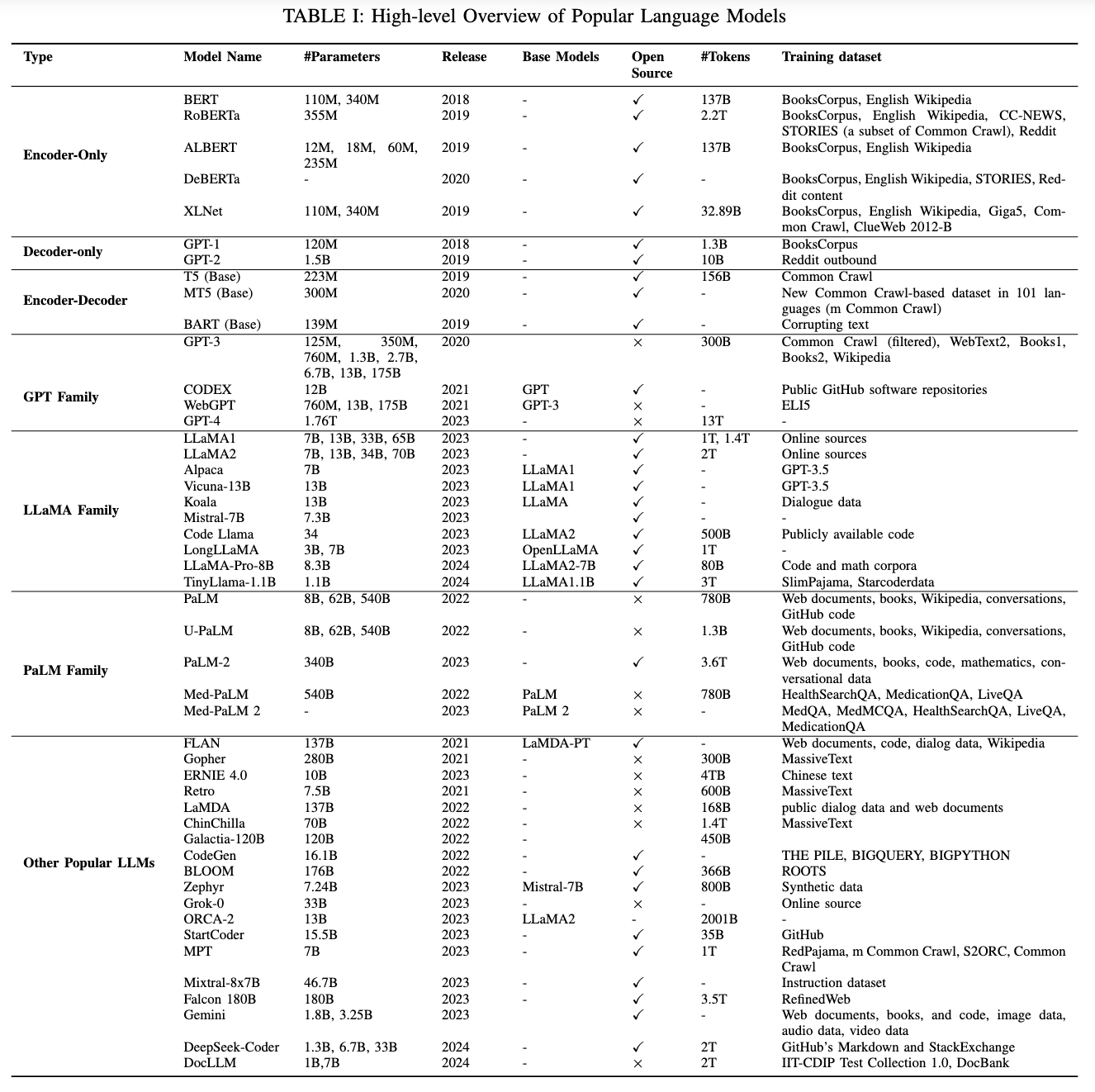
대형 언어 모델(LLMs)은 주로 PaLM [31], LLaMA [32], GPT-4 [33]와 같이 수십억에서 수백억 개의 파라미터를 포함하며, 방대한 텍스트 데이터를 사전 학습한 트랜스포머 기반 신경 언어 모델을 지칭한다(Table III 참조). PLMs(사전 학습 언어 모델)과 비교했을 때, LLM은 단순히 모델 크기가 훨씬 클 뿐만 아니라, 더 강력한 언어 이해 및 생성 능력을 보여주며, 특히 소규모 언어 모델에서는 나타나지 않는 발현 능력(emergent abilities)을 보인다.
Fig. 1에 설명된 이러한 발현 능력은 다음과 같다:
1. 맥락 내 학습(in-context learning): LLM이 추론 시 프롬프트에 제시된 소량의 예제를 기반으로 새로운 작업을 학습하는 능력.
2. 지침 준수(instruction following): 지침 튜닝(instruction tuning) 이후, 명시적인 예제 없이 새로운 유형의 작업 지침을 따를 수 있는 능력.
3. 다단계 추론(multi-step reasoning): 복잡한 작업을 중간 추론 단계를 거쳐 해결하는 능력(chain-of-thought prompt에서 시연됨) [34].
또한, LLM은 외부 지식과 도구를 활용하여 [35], [36], 사용자 및 환경과 효과적으로 상호작용하고 [37], 상호작용을 통해 수집된 피드백 데이터를 사용하여 스스로 지속적으로 개선할 수 있다(예: 인간 피드백을 활용한 강화 학습(RLHF)).
이러한 고급 활용 및 확장 기술을 통해, LLM은 환경을 감지하고, 의사 결정을 내리며, 행동을 취하는 AI 에이전트로 배치될 수 있다. 기존 연구는 특정 작업 및 도메인을 위한 에이전트 개발에 초점을 맞추었으나, LLM이 보여주는 발현 능력 덕분에 LLM 기반 범용 AI 에이전트를 구축할 수 있는 가능성이 열렸다.
LLM은 정적인 환경에서 응답을 생성하도록 학습되었지만, AI 에이전트는 동적인 환경과 상호작용하기 위해 행동을 취해야 한다.
따라서, LLM 기반 에이전트는 외부 지식 베이스에서 최신 정보를 얻거나, 시스템 행동이 기대한 결과를 생성하는지 검증하거나, 예상대로 진행되지 않는 상황에 대처하기 위해 LLM을 확장해야 한다.
본 논문의 나머지 구성은 다음과 같다:
- Section II: GPT, LLaMA, PaLM을 포함한 주요 LLM 계열 및 대표적인 모델에 초점을 맞추어 LLM의 최신 상태를 개괄.
- Section III: LLM이 구축되는 방식을 논의.
- Section IV: LLM이 실제 응용에서 어떻게 사용되고 확장되는지를 논의.
- Sections V 및 VI: LLM을 평가하기 위한 주요 데이터셋과 벤치마크를 검토하고, 보고된 LLM 평가 결과를 요약.
- Section VII: LLM 연구의 과제와 미래 연구 방향을 요약하며 논문을 마무리.
2 Large Language Models
이 섹션에서는 LLM의 기반이 되는 초기 사전 학습 신경 언어 모델(Pre-trained Neural Language Models)을 검토하고, 이어서 GPT, LLaMA, PaLM이라는 세 가지 LLM 계열에 초점을 맞춰 논의한다. Table I은 이러한 모델들과 그 특성에 대한 개요를 제공한다.
A. Early Pre-trained Neural Language Models
신경망을 사용한 언어 모델링은 [38], [39], [40]에 의해 개척되었다. Bengio 등[13]은 n-그램 모델과 비교할 수 있는 초기 신경 언어 모델(NLM)을 개발했다. 이후, [14]는 NLM을 기계 번역에 성공적으로 적용했다. Mikolov[41], [42]이 RNNLM(오픈 소스 NLM 툴킷)을 발표하면서 NLM의 대중화가 크게 촉진되었다. 이후, 순환 신경망(RNN)과 장단기 메모리(LSTM)[19], 게이트 순환 유닛(GRU)[20]과 같은 변형을 기반으로 한 NLM이 기계 번역, 텍스트 생성, 텍스트 분류를 포함한 다양한 자연어 응용에서 널리 사용되었다[43].
트랜스포머(Transformer) 아키텍처[44]의 발명은 NLM 개발의 또 다른 이정표를 세웠다. 트랜스포머는 문장이나 문서의 모든 단어에 대해 "어텐션 점수(attention score)"를 계산하여 각 단어가 다른 단어에 미치는 영향을 모델링하기 위해 셀프 어텐션(self-attention)을 병렬로 적용한다. 이는 RNN보다 훨씬 더 많은 병렬 처리를 가능하게 하며, GPU를 활용해 대규모 데이터에서 매우 큰 언어 모델을 효율적으로 사전 학습할 수 있게 한다. 이렇게 사전 학습된 언어 모델(PLM)은 다양한 후속 작업(downstream tasks)에 맞게 미세 조정(fine-tuning)될 수 있다.
초기 트랜스포머 기반 PLM은 신경망 아키텍처에 따라 세 가지 주요 범주로 나눌 수 있다: 인코더 전용 모델, 디코더 전용 모델, 인코더-디코더 모델. 초기 PLM에 대한 포괄적인 설문 연구는 [43], [28]에서 제공된다.
1) 인코더 전용 PLM (Encoder-only PLMs)
이름에서 알 수 있듯이, 인코더 전용 모델은 인코더 네트워크로만 구성되어 있다. 이러한 모델은 주로 텍스트 분류와 같이 입력 텍스트에 대해 클래스 레이블을 예측해야 하는 언어 이해 작업을 위해 개발되었다. 대표적인 인코더 전용 모델로는 BERT와 그 변형 모델들(e.g., RoBERTa, ALBERT, DeBERTa, XLM, XLNet, UNILM)이 있다.
BERT

BERT(Bidirectional Encoder Representations from Transformers) [24]는 가장 널리 사용되는 인코더 전용 언어 모델 중 하나이다. BERT는 다음과 같은 세 가지 모듈로 구성된다:
1. 임베딩 모듈: 입력 텍스트를 임베딩 벡터 시퀀스로 변환.
2. 트랜스포머 인코더 스택: 임베딩 벡터를 컨텍스트 표현 벡터로 변환.
3. 완전 연결 계층: 최종 계층의 표현 벡터를 원-핫 벡터로 변환.
BERT는 마스크 언어 모델링(MLM)과 다음 문장 예측(next sentence prediction)이라는 두 가지 목표로 사전 학습된다. 사전 학습된 BERT 모델은 분류기 계층을 추가하여 텍스트 분류, 질문 응답, 언어 추론과 같은 다양한 언어 이해 작업에 맞게 미세 조정(fine-tuning)될 수 있다. Fig. 3은 BERT 프레임워크의 높은 수준의 개요를 보여준다. BERT는 발표 당시 언어 이해 작업에서 최첨단 성능(state of the art)을 크게 향상시켜, AI 커뮤니티가 BERT를 기반으로 한 많은 유사 인코더 전용 언어 모델을 개발하도록 영감을 주었다.
RoBERTa
RoBERTa [25]는 몇 가지 모델 설계 선택 및 학습 전략을 사용하여 BERT의 견고성을 크게 향상시켰다. 예를 들어, 몇 가지 주요 하이퍼파라미터를 수정하고, 다음 문장 예측 목표를 제거하며, 훨씬 더 큰 미니배치 크기와 학습률로 학습을 진행했다.
ALBERT
ALBERT [45]는 두 가지 파라미터 감소 기법을 사용하여 BERT의 메모리 소비를 줄이고 학습 속도를 증가시켰다:
1. 임베딩 매트릭스를 두 개의 더 작은 매트릭스로 분할.
2. 그룹 간에 분할된 반복 계층 사용.
DeBERTa
DeBERTa(Decoding-enhanced BERT with disentangled attention) [26]는 두 가지 새로운 기술을 사용하여 BERT 및 RoBERTa 모델을 개선했다.
1. 분리된 어텐션 메커니즘(disentangled attention mechanism): 각 단어를 내용(content)과 위치(position)를 각각 인코딩하는 두 개의 벡터로 표현하며, 단어 간 어텐션 가중치는 내용과 상대적 위치를 기준으로 분리된 행렬을 사용해 계산된다.
2. 강화된 마스크 디코더(enhanced mask decoder): 모델 사전 학습에서 마스크된 토큰을 예측하기 위해 디코딩 계층에 절대 위치 정보를 통합.
또한, 모델의 일반화를 개선하기 위해 새로운 가상 적대적 학습 방법(virtual adversarial training)이 미세 조정 과정에서 사용된다.
ELECTRA

ELECTRA [46]는 대체 토큰 감지(replaced token detection, RTD)라는 새로운 사전 학습 작업을 사용하며, 이는 MLM보다 샘플 효율성이 높은 것으로 입증되었다. RTD는 입력을 마스킹하는 대신, 일부 토큰을 작은 생성기 네트워크에서 샘플링한 그럴듯한 대체 토큰으로 교체하여 입력을 손상시킨다. 그런 다음, 손상된 토큰의 원래 정체성을 예측하는 모델을 학습하는 대신, 손상된 입력에서 토큰이 생성된 샘플로 대체되었는지를 예측하는 판별 모델을 학습한다. RTD는 입력 토큰 전체를 대상으로 정의되므로, 마스킹된 소수의 토큰만 사용하는 MLM보다 샘플 효율성이 더 높다(Fig. 4 참고).
XLMs
XLMs [47]은 BERT를 확장하여 다국어 언어 모델을 개발했으며, 두 가지 방법을 사용했다:
1. 비지도 학습 방법: 단일 언어 데이터에만 의존.
2. 지도 학습 방법: 병렬 데이터를 활용하여 새로운 다국어 언어 모델 목표를 적용(Fig. 5 참조).
XLMs는 제안 당시 다국어 분류, 비지도 및 지도 학습 기반 기계 번역에서 최첨단 성능(state-of-the-art)을 달성했다.
XLNet과 UNILM
인코더 전용 언어 모델 중에서도 자동회귀(decoder) 모델의 장점을 활용하여 모델 학습과 추론을 진행하는 사례도 있다. XLNet과 UNILM이 그 예이다.

- XLNet [48]: Transformer-XL에 기반하며, 모든 팩터라이제이션 순열에 대한 기대 가능성을 최대화하여 양방향 문맥을 학습할 수 있는 일반화된 자동회귀 방법을 사용해 사전 학습된다.
- UNILM (UNIfied pre-trained Language Model) [49]: 한 방향(unidirectional), 양방향(bidirectional), 시퀀스-투-시퀀스(sequence-to-sequence) 예측을 포함한 세 가지 언어 모델링 작업으로 사전 학습된다. 이를 위해 공유된 Transformer 네트워크를 사용하며, 특정 셀프 어텐션 마스크를 활용해 예측이 어떤 문맥에 조건화되는지를 제어한다(Fig. 6 참조). 이 사전 학습된 모델은 자연어 이해 및 생성 작업 모두에 미세 조정할 수 있다.

2) 디코더 전용 PLMs
디코더 전용 PLMs 중 가장 널리 사용되는 모델은 OpenAI가 개발한 GPT-1과 GPT-2이다. 이 모델들은 이후 더 강력한 LLM(GPT-3, GPT-4)로 이어지는 토대를 마련했다.
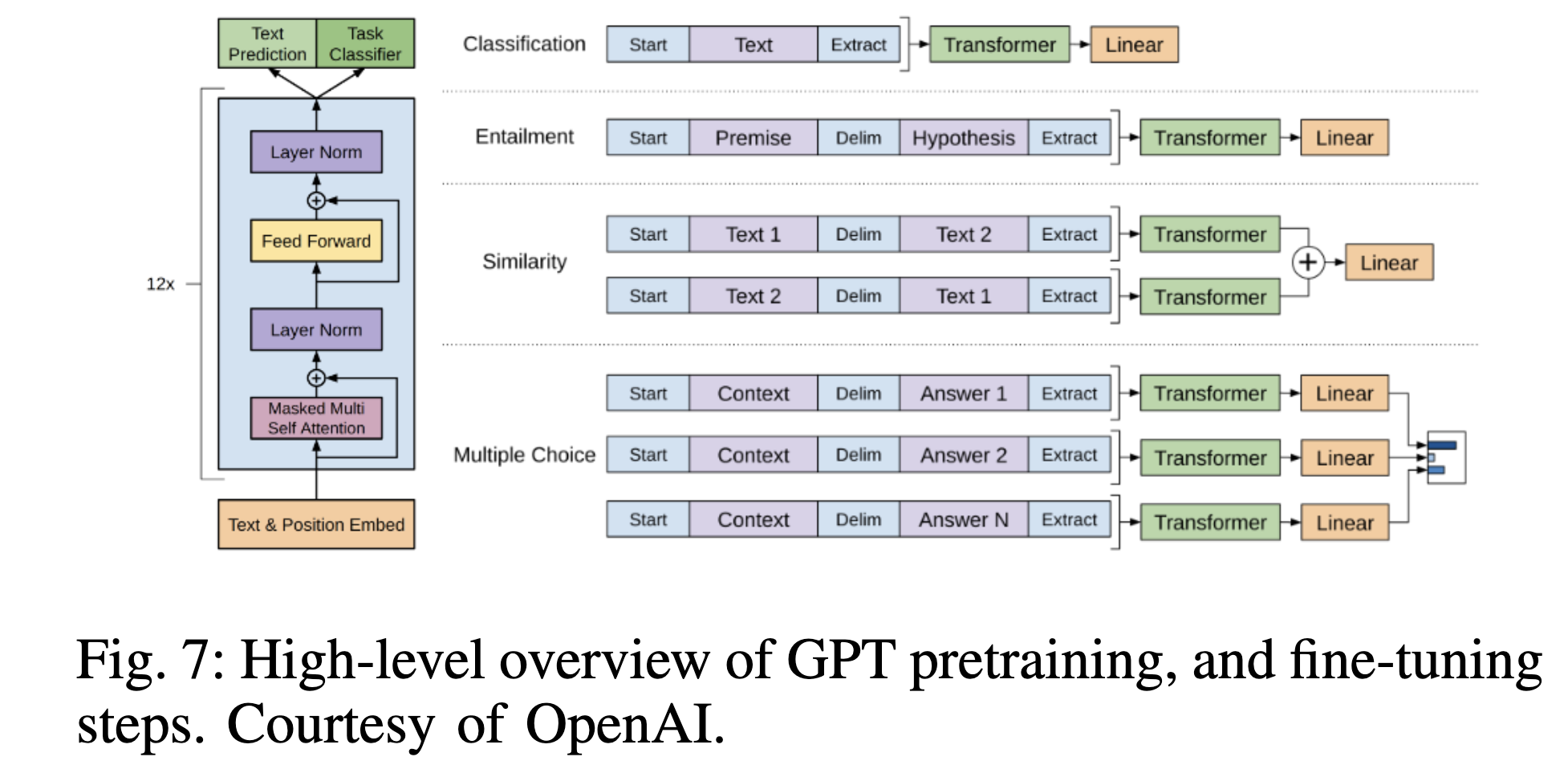
GPT-1
GPT-1 [50]은 디코더 전용 트랜스포머 모델을 다양한 라벨이 없는 텍스트 코퍼스에 대해 생성 사전 학습(Generative Pre-Training, GPT) 방식으로 학습하고, 각 특정 후속 작업에 대해 소량의 데이터로 판별 미세 조정(discriminative fine-tuning)을 수행하여 폭넓은 자연어 작업에서 좋은 성능을 얻을 수 있음을 처음으로 시연했다(Fig. 7 참조). GPT-1은 이후 GPT 모델 개발의 길을 열었으며, 각 버전이 아키텍처를 개선하고 다양한 언어 작업에서 더 나은 성능을 달성했다.
GPT-2
GPT-2 [51]는 수백만 개의 웹 페이지로 구성된 대규모 WebText 데이터셋으로 학습할 때, 언어 모델이 명시적인 감독 없이도 특정 자연어 작업을 수행하는 방법을 학습할 수 있음을 보여주었다. GPT-2는 GPT-1의 모델 설계를 따르면서 몇 가지 수정 사항을 추가했다:
- 레이어 정규화(layer normalization)를 각 서브 블록의 입력으로 이동.
- 마지막 셀프 어텐션 블록 이후 추가 레이어 정규화를 추가.
- 잔여 경로(residual path)에서 누적 효과를 고려하기 위해 초기화를 수정하고, 잔여 계층의 가중치를 스케일링.
- 어휘 크기를 50,257로 확장.
- 문맥 크기를 512 토큰에서 1024 토큰으로 증가.
3) 인코더-디코더 PLMs
Raffle 등[52]은 거의 모든 NLP 작업이 시퀀스-투-시퀀스(sequence-to-sequence) 생성 작업으로 변환될 수 있음을 보여주었다. 따라서 인코더-디코더 언어 모델은 설계상 모든 자연어 이해 및 생성 작업을 수행할 수 있는 통합 모델(unified model)이다. 여기서 검토할 대표적인 인코더-디코더 PLM으로는 T5, mT5, MASS, BART가 있다.
T5
T5(Text-to-Text Transfer Transformer) [52]는 모든 NLP 작업을 텍스트-투-텍스트 생성 작업으로 변환하는 통합 프레임워크를 도입하여, NLP에서 전이 학습(transfer learning)을 효과적으로 활용하는 모델이다.
mT5
mT5 [53]는 T5의 다국어 변형 모델로, 101개 언어의 텍스트로 구성된 새로운 Common Crawl 기반 데이터셋으로 사전 학습되었다.
MASS
MASS(MAsked Sequence to Sequence pre-training) [54]는 인코더-디코더 프레임워크를 채택하여 문장의 일부를 주어진 나머지 부분으로 재구성한다.
- 인코더: 임의로 연속된 여러 토큰이 마스킹된 문장을 입력으로 받아들인다.
- 디코더: 마스킹된 부분을 예측한다.
이 방식으로 MASS는 언어 임베딩(language embedding)을 위한 인코더와 언어 생성을 위한 디코더를 공동으로 학습한다.
BART
BART [55]는 표준 시퀀스-투-시퀀스 번역 모델 아키텍처를 사용한다. 텍스트를 임의의 노이즈 함수로 손상시키고, 원래 텍스트를 복원하도록 학습시키는 방식으로 사전 학습된다.
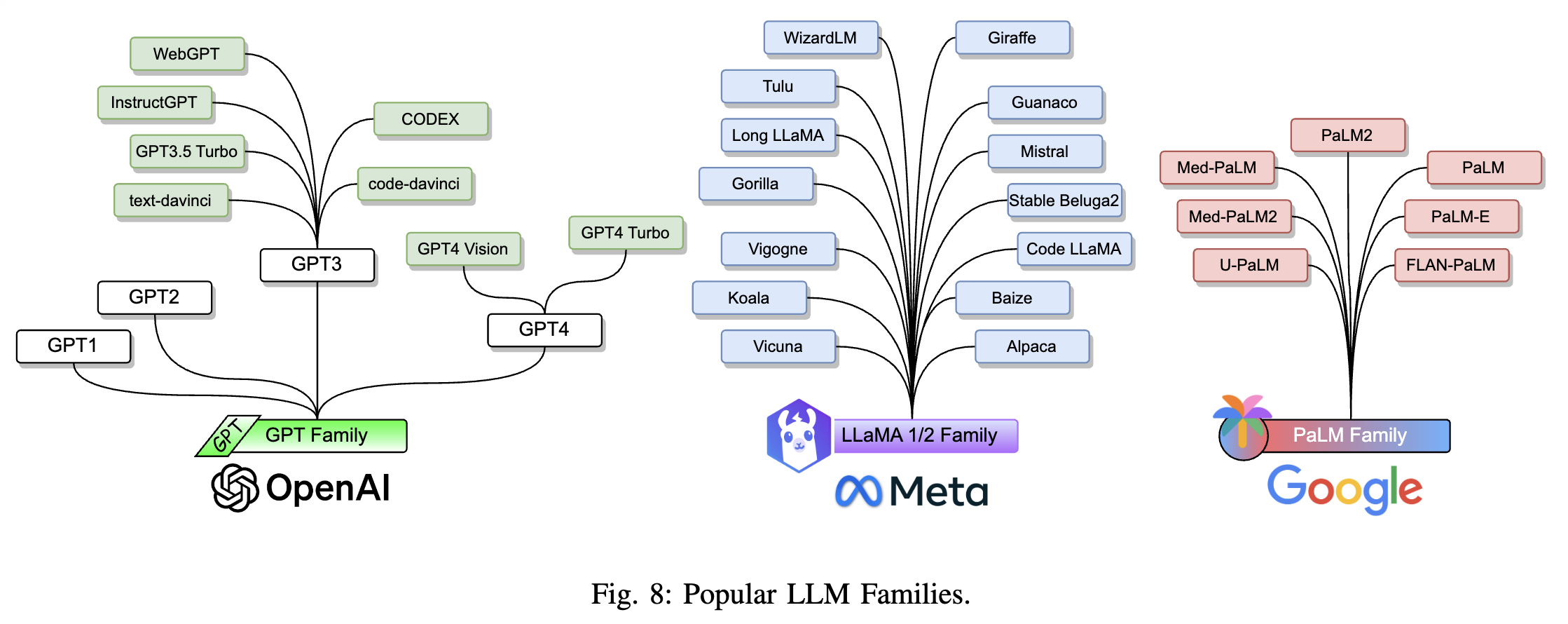
B. 대형 언어 모델 계열 (Large Language Model Families)
대형 언어 모델(LLMs)은 주로 수십억에서 수백억 개의 파라미터를 포함하는 트랜스포머 기반 PLMs를 지칭한다. 앞서 검토한 PLMs와 비교했을 때, LLM은 단순히 모델 크기가 더 큰 것뿐만 아니라 더 강력한 언어 이해 및 생성 능력과, 작은 모델에서는 관찰되지 않는 발현 능력(emergent abilities)을 보여준다. 이하에서는 Fig. 8에 설명된 세 가지 LLM 계열인 GPT, LLaMA, PaLM을 검토한다.
1) GPT 계열
GPT(Generative Pre-trained Transformers)는 OpenAI가 개발한 디코더 전용 트랜스포머 기반 언어 모델 계열로, GPT-1, GPT-2, GPT-3, InstructGPT, ChatGPT, GPT-4, CODEX, WebGPT 등이 포함된다. GPT-1과 GPT-2는 오픈소스로 제공되었지만, 최근의 GPT-3와 GPT-4는 비공개로 유지되며 API를 통해서만 접근 가능하다. GPT-1과 GPT-2는 앞서 PLM 섹션에서 논의되었으며, 아래에서는 GPT-3부터 시작한다.
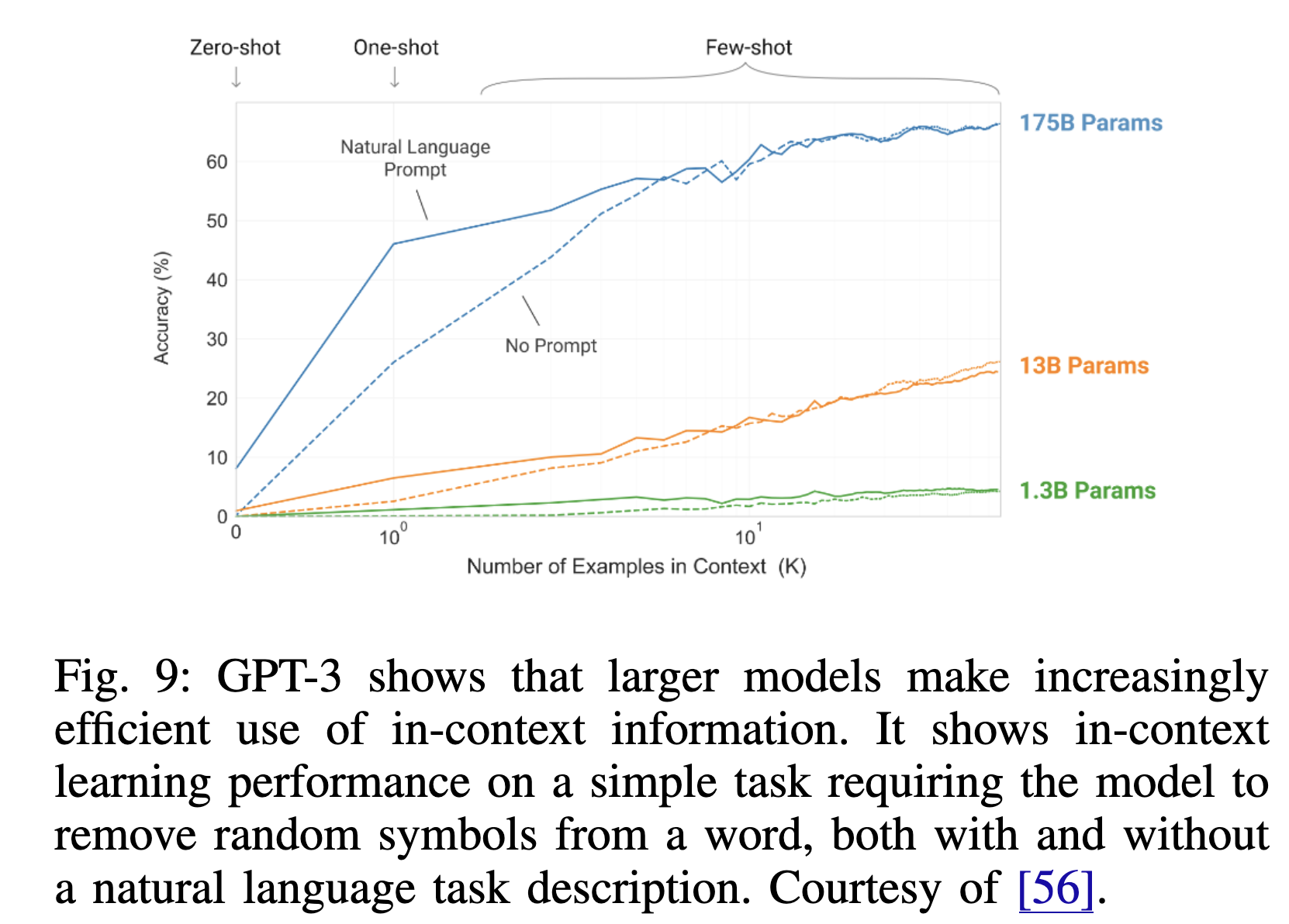
GPT-3
GPT-3 [56]는 175억 개의 파라미터를 가진 사전 학습된 자동회귀 언어 모델이다. GPT-3는 이전 PLMs보다 훨씬 큰 모델일 뿐만 아니라, 이전의 작은 PLMs에서는 관찰되지 않았던 발현 능력을 처음으로 시연하며 LLM으로 널리 간주된다.
- GPT-3는 맥락 내 학습(in-context learning)이라는 발현 능력을 보여준다. 이는 작업 및 소수 샷 예제를 텍스트 상호작용을 통해 지정하여, 어떠한 그래디언트 업데이트나 미세 조정 없이 후속 작업에 적용할 수 있음을 의미한다.
- GPT-3는 번역, 질문 응답, 클로즈(cloze) 작업 등 많은 NLP 작업에서 강력한 성능을 보였으며, 단어 재배열, 새로운 단어를 문장에서 사용, 3자리 숫자 산술과 같은 즉석 추론이나 도메인 적응이 필요한 작업에서도 우수한 성과를 냈다(Fig. 9 참조).
CODEX
CODEX [57]는 OpenAI가 2023년 3월에 발표한 범용 프로그래밍 모델로, 자연어를 해석하고 이에 응답하는 코드를 생성할 수 있다. CODEX는 GPT-3의 후속 모델로, GitHub에서 수집된 코드 데이터셋을 사용해 프로그래밍 응용에 맞게 미세 조정되었다. CODEX는 Microsoft의 GitHub Copilot을 지원한다.
WebGPT
WebGPT [58]는 또 다른 GPT-3의 후속 모델로, 텍스트 기반 웹 브라우저를 사용하여 열린 질문에 응답하도록 미세 조정되었다. WebGPT는 사용자가 웹을 검색하고 탐색할 수 있도록 지원한다.
WebGPT는 다음 세 단계를 통해 학습된다:
1. 인간 시범 데이터를 사용하여 인간의 브라우징 동작을 모방하도록 학습.
2. 인간의 선호를 예측하는 보상 함수를 학습.
3. 보상 함수를 최적화하기 위해 강화 학습과 거부 샘플링(rejection sampling)을 사용하여 WebGPT를 개선.
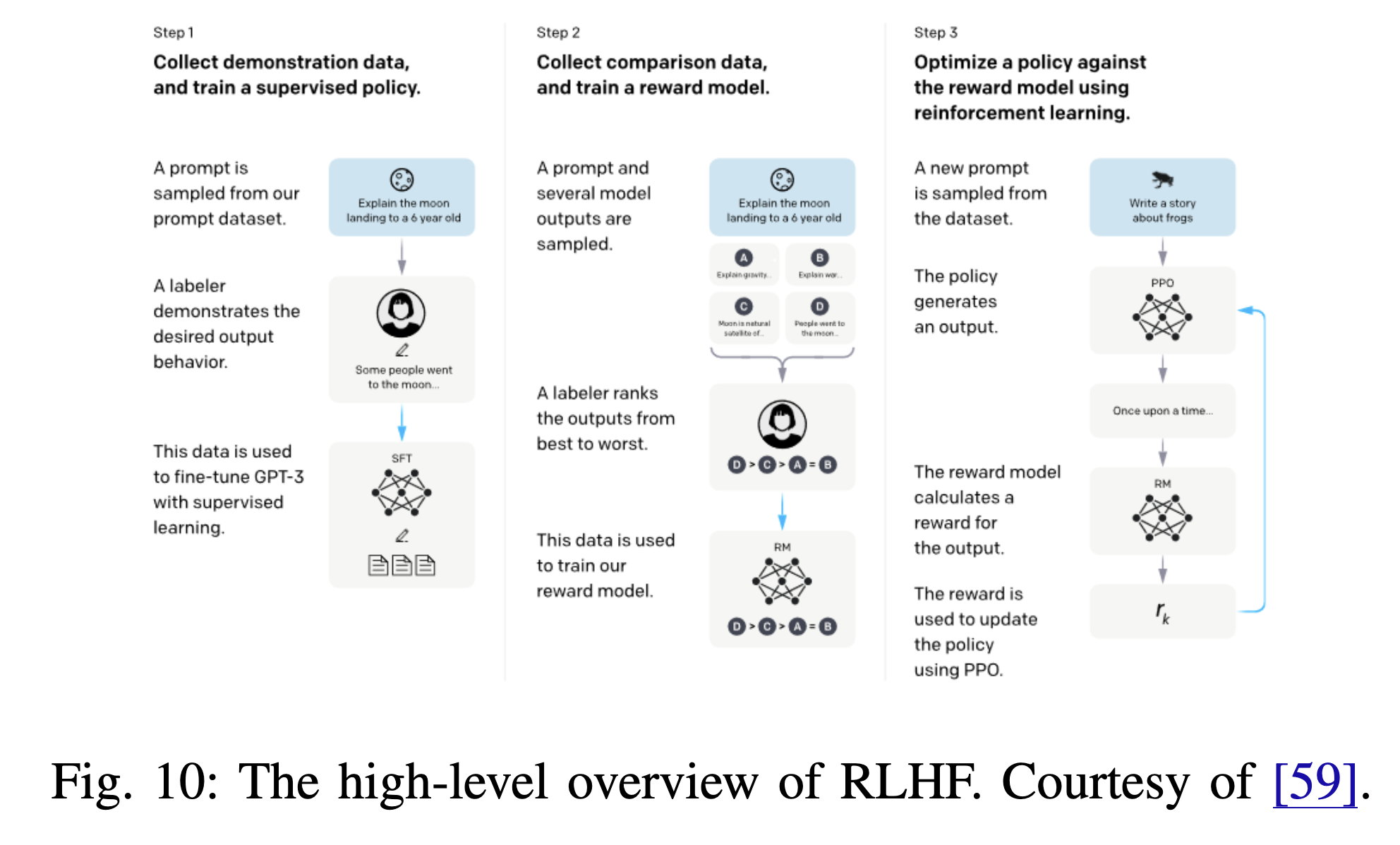
InstructGPT
InstructGPT [59]는 LLM이 사용자의 의도를 따르도록 하기 위해, 인간 피드백을 활용한 미세 조정을 통해 언어 모델을 사용자 의도에 맞추는 모델이다.
- OpenAI API를 통해 제출된 라벨러가 작성한 프롬프트와 프롬프트 세트를 시작으로, 원하는 모델 동작을 시연한 라벨러 데모 데이터셋을 수집한다.
- 그런 다음, GPT-3를 이 데이터셋으로 미세 조정한다.
- 이후, 인간이 모델 출력물을 순위 매긴 데이터셋을 수집하여 인간 피드백을 활용한 강화 학습(Reinforcement Learning from Human Feedback, RLHF) 방법으로 모델을 추가로 미세 조정한다.
(RLHF)로 미세 조정된 InstructGPT 모델은 진실성과 독성 출력 감소에서 개선을 보였으며, 공개 NLP 데이터셋에서는 최소한의 성능 퇴보만 나타냈다(Fig. 10 참조).
ChatGPT의 출범
LLM 개발에서 가장 중요한 이정표는 2022년 11월 30일에 출시된 ChatGPT (Chat Generative Pre-trained Transformer) [60]이다. ChatGPT는 사용자가 대화를 조정하여 질문 응답, 정보 검색, 텍스트 요약 등 다양한 작업을 수행할 수 있도록 하는 챗봇이다.
ChatGPT는 InstructGPT와 동일한 계열의 모델인 GPT-3.5(이후 GPT-4)로 구동되며, 프롬프트에 포함된 지침을 따르고 세부적인 응답을 제공하도록 학습되었다.
GPT-4
GPT-4 [33]는 GPT 계열의 최신이자 가장 강력한 LLM이다. 2023년 3월에 출시된 GPT-4는 멀티모달 LLM으로, 이미지와 텍스트를 입력받아 텍스트 출력을 생성할 수 있다.
- GPT-4는 일부 현실 세계의 어려운 시나리오에서는 여전히 인간보다 성능이 떨어지지만, 모의 변호사 시험에서 상위 10%의 점수로 합격하는 등 다양한 전문 및 학술 벤치마크에서 인간 수준의 성능을 보여준다(Fig. 11 참조).
- 이전 GPT 모델들과 마찬가지로, GPT-4는 대규모 텍스트 코퍼스에서 다음 토큰을 예측하도록 사전 학습된 후, RLHF를 통해 인간이 원하는 행동에 모델을 정렬하도록 미세 조정되었다.
2) LLaMA 계열
LLaMA는 Meta에서 발표한 기초 언어 모델(foundation language models)이다. GPT 모델과 달리, LLaMA 모델은 오픈소스로 제공되며, 모델 가중치가 비상업적 라이선스 하에 연구 커뮤니티에 공개되었다. 이로 인해 많은 연구 그룹이 이 모델을 사용하여 보다 나은 오픈소스 LLM을 개발하거나, 중요한 작업을 위한 특정 작업에 최적화된 LLM을 개발할 수 있게 되었다.
- 첫 번째 LLaMA 모델 세트 [32]는 2023년 2월에 출시되었으며, 7B에서 65B 파라미터까지의 모델을 포함한다. 이 모델들은 공개적으로 사용 가능한 데이터셋에서 수집된 수조 개의 토큰으로 사전 학습되었다.
- LLaMA는 GPT-3의 트랜스포머 아키텍처를 사용하지만, 다음과 같은 몇 가지 사소한 구조적 수정이 포함되어 있다:
1. ReLU 대신 SwiGLU 활성화 함수 사용.
2. 절대 위치 임베딩 대신 회전 위치 임베딩(rotary positional embedding) 사용.
3. 표준 레이어 정규화 대신 제곱 평균 루트 레이어 정규화(root-mean-squared layer-normalization) 사용.
오픈소스 모델인 LLaMA-13B는 대부분의 벤치마크에서 GPT-3 (175B) 모델을 능가하여 LLM 연구의 우수한 기준점으로 평가받는다.
LLaMA-2
2023년 7월, Meta는 Microsoft와 협력하여 LLaMA-2 모델 세트를 발표했다 [61]. LLaMA-2는 기초 언어 모델과 대화용으로 미세 조정된 LLaMA-2 Chat 모델을 포함한다.
- LLaMA-2 Chat 모델은 많은 공개 벤치마크에서 다른 오픈소스 모델을 능가한 것으로 보고되었다.
- Fig. 12는 LLaMA-2 Chat의 학습 과정을 보여준다:
1. LLaMA-2는 공개적으로 사용 가능한 온라인 데이터를 사용해 사전 학습된다.
2. 이후, 지도 학습(supervised fine-tuning)을 통해 초기 LLaMA-2 Chat 모델이 구축된다.
3. 마지막으로, RLHF, 거부 샘플링(rejection sampling), 근접 정책 최적화(proximal policy optimization)를 사용하여 모델이 반복적으로 개선된다.
RLHF 단계에서는 보상 모델의 수정으로 인해 모델 학습 안정성이 손상되지 않도록, 보상 모델을 수정하는 인간 피드백의 축적이 중요하다.
Alpaca
Alpaca [62]는 LLaMA-7B 모델을 기반으로 GPT-3.5(text-davinci-003)를 사용해 Self-Instruct 스타일로 생성된 52,000개의 지침 따르기(demonstration) 데이터를 활용해 미세 조정(fine-tuning)된 모델이다.
- Alpaca는 학술 연구에서 특히 비용 효율적인 훈련을 제공한다.
- Self-Instruct 평가 세트에서 Alpaca는 훨씬 더 작은 크기에도 불구하고 GPT-3.5와 유사한 성능을 보여준다.
Vicuna
Vicuna 팀은 ShareGPT에서 수집된 사용자 대화 데이터를 활용해 LLaMA를 미세 조정하여 13B 채팅 모델(Vicuna-13B)을 개발했다.
- GPT-4를 평가자로 사용한 초기 평가에 따르면, Vicuna-13B는 OpenAI의 ChatGPT 및 Google Bard 성능의 90% 이상에 도달하며, LLaMA 및 Stanford Alpaca와 같은 다른 모델보다 90% 이상의 사례에서 더 우수한 성능을 보여준다(Fig. 13 참조).
- Vicuna-13B의 또 다른 장점은 상대적으로 낮은 훈련 비용으로, 단 $300만 소요된다.
Guanaco
Guanaco 모델 [63]은 Alpaca 및 Vicuna와 마찬가지로 LLaMA를 기반으로 지침 데이터를 사용해 미세 조정되었지만, QLoRA를 사용하여 매우 효율적으로 훈련된다.
- 65B 파라미터 모델도 단일 48GB GPU에서 미세 조정이 가능하다.
- QLoRA는 고정된 4비트 양자화된 사전 학습 언어 모델을 통해 그래디언트를 역전파하여 Low Rank Adapters(LoRA)로 전달한다.
- 최고 성능의 Guanaco 모델은 Vicuna 벤치마크에서 이전에 발표된 모든 모델을 능가하며, ChatGPT 성능의 99.3%에 도달했다. 이 모든 것이 단일 GPU에서 24시간의 미세 조정만으로 이루어진다.
Koala
Koala [64]는 LLaMA를 기반으로 구축된 또 다른 지침 따르기 언어 모델로, ChatGPT와 같은 고성능 비공개 채팅 모델이 생성한 사용자 입력 및 응답 데이터를 포함한 상호작용 데이터에 중점을 둔다.
- Koala-13B 모델은 실제 사용자 프롬프트를 기반으로 한 인간 평가에서 최첨단 채팅 모델과 경쟁할 만한 성능을 보인다.
Mistral-7B
Mistral-7B [65]는 성능과 효율성을 극대화하도록 설계된 7B 파라미터 언어 모델이다.
- Mistral-7B는 평가된 모든 벤치마크에서 LLaMA-2-13B를 포함한 최고 오픈소스 13B 모델을 능가하며, LLaMA-34B 모델보다도 추론, 수학, 코드 생성에서 더 우수하다.
- 이 모델은 Grouped-query Attention을 활용해 추론 속도를 높이고, 슬라이딩 윈도우 어텐션을 적용해 임의 길이의 시퀀스를 더 낮은 추론 비용으로 효과적으로 처리한다.
LLaMA 기반 확장
LLaMA 계열은 LLaMA 또는 LLaMA-2를 기반으로 한 다양한 지침 따르기 모델이 개발됨에 따라 빠르게 성장하고 있다. 여기에는 다음과 같은 모델이 포함된다:
- Code LLaMA [66]
- Gorilla [67]
- Giraffe [68]
- Vigogne [69]
- Tulu 65B [70]
- Long LLaMA [71]
- Stable Beluga2 [72]
위 모델들은 일부 예시에 불과하며, LLaMA 기반 연구는 지속적으로 확장되고 있다.
3) The PaLM Family
PaLM(Pathways Language Model) 패밀리는 Google에서 개발했다. 첫 번째 PaLM 모델 [31]은 2022년 4월에 발표되었으며 2023년 3월까지 비공개로 유지되었다. 이 모델은 5,400억 개의 매개변수를 가진 Transformer 기반 대규모 언어 모델(LLM)이다. PaLM은 7800억 개의 토큰으로 구성된 고품질 텍스트 코퍼스를 사용하여 다양한 자연어 작업 및 사용 사례에 대해 사전 학습되었다. 이 모델은 Pathways 시스템을 사용하여 6144개의 TPU v4 칩에서 학습되며, 다수의 TPU Pod에서 고도로 효율적인 학습을 가능하게 한다.
PaLM은 확장에 따른 지속적인 이점을 보여주며, 수백 개의 언어 이해 및 생성 벤치마크에서 최신의 소수 샷 학습(few-shot learning) 결과를 달성했다. PaLM-540B는 다단계 추론 작업에서 최신의 미세 조정된 모델뿐만 아니라 인간 수준에 필적하는 성능을 최근 발표된 BIG-bench 벤치마크에서 보였다.
U-PaLM 모델은 8B, 62B, 540B 규모로 구성되며 UL2R(UL2의 혼합 디노이저 목표를 몇 단계에 걸쳐 사용하여 LLM을 계속 학습시키는 방법)을 통해 PaLM에 지속적으로 학습되었고, 약 2배의 계산 절약 효과가 보고되었다.
U-PaLM은 이후 Flan-PaLM으로 명령어 기반 미세 조정되었다 [74]. 기존의 명령어 기반 미세 조정 작업과 비교했을 때, Flan-PaLM의 미세 조정은 훨씬 더 많은 작업, 더 큰 모델 크기 및 체인 오브 쏘트(chain-of-thought) 데이터를 사용하여 수행한다. 그 결과, Flan-PaLM은 이전 명령어 기반 모델보다 크게 향상된 성능을 보여주는데, 예를 들어, Flan-PaLM-540B는 1,800개의 작업에 대해 명령어 기반으로 미세 조정되었으며, PaLM-540B보다 평균적으로 9.4% 더 높은 성능을 보였다. 미세 조정 데이터는 473개의 데이터셋, 146개의 작업 범주, 1836개의 작업으로 구성되어 있다(그림 14 참고).
PaLM-2 [75]는 이전 버전인 PaLM에 비해 더 높은 계산 효율성과 더 나은 다국어 및 추론 능력을 가진 LLM이다. PaLM-2는 혼합 목표를 사용하여 학습되었다. 영어, 다국어 및 추론 작업에 대한 광범위한 평가를 통해 PaLM-2는 다양한 모델 크기에서 다운스트림 작업 성능을 크게 향상시키는 동시에 PaLM보다 더 빠르고 효율적인 추론을 제공한다.
Med-PaLM [76]은 의료 질문에 대한 고품질 답변을 제공하도록 설계된 분야 특화된 PaLM이다. Med-PaLM은 소수의 예제를 사용하여 LLM을 새로운 도메인에 정렬하는 매개변수 효율적인 방법인 명령어 프롬프트 조정을 통해 PaLM에서 미세 조정되었다. Med-PaLM은 많은 의료 작업에서 매우 고무적인 결과를 얻었지만, 여전히 인간 임상의에 비해 부족한 면이 있다.
Med-PaLM 2는 의료 도메인 미세 조정과 앙상블 프롬프트를 통해 Med-PaLM을 개선했다 [77]. Med-PaLM 2는 MedQA 데이터셋(전문 의료 시험, 연구 및 소비자 질문을 포괄하는 여섯 개의 기존 오픈 질문 답변 데이터셋을 결합한 벤치마크)에서 최대 86.5%의 점수를 기록하며 Med-PaLM보다 19% 이상 개선된 성능을 보여 새로운 최신 기록을 세웠다.
C) Other Representative LLMs (기타 대표적인 LLM들)
위에서 언급된 모델 패밀리 외에도, LLMs 분야를 발전시키고 뛰어난 성능을 달성한 인기 있는 모델들이 있다. 이 섹션에서는 이러한 LLM들을 간략히 설명한다.
FLAN: Wei et al. [78]은 언어 모델의 제로샷 학습 능력을 개선하는 간단한 방법을 탐구했습니다. 이들은 자연어 설명 템플릿을 통해 설명된 데이터셋 모음에서 명령어 기반으로 언어 모델을 튜닝하는 것이 보지 못한 작업에서의 제로샷 성능을 상당히 향상시킨다는 것을 보여주었습니다. 이들은 137B 매개변수 사전 학습 언어 모델을 사용해 60개 이상의 NLP 데이터셋에서 명령어 튜닝을 수행했으며, 이를 FLAN이라고 명명했습니다. 그림 15는 명령어 튜닝과 사전 학습-미세 조정 및 프롬프트 기반 접근법을 비교합니다.
Gopher: Rae et al. [79]는 다양한 모델 크기에 걸쳐 Transformer 기반 언어 모델 성능을 분석했습니다. 이들은 수천만 개의 매개변수를 가진 모델에서 2800억 개의 매개변수를 가진 모델(Gopher)에 이르기까지 152개의 다양한 작업에서 모델을 평가하며 최신 성능을 달성했습니다. 다양한 모델 크기에 따른 레이어 수, key/value 크기 등 하이퍼파라미터는 그림 16에 나타나 있습니다.
T0: Sanh et al. [80]은 자연어 작업을 인간이 읽을 수 있는 프롬프트 형태로 쉽게 매핑할 수 있는 시스템인 T0를 개발했습니다. 이들은 다양한 문구로 구성된 여러 프롬프트를 포함한 감독 데이터셋 세트를 변환했습니다. 이 프롬프트 데이터셋은 모델이 완전히 새로운 작업을 수행할 수 있는 능력을 평가하는 데 사용됩니다. 이후 텍스트 입력을 소비하고 대상 응답을 생성하는 T0 인코더-디코더 모델이 개발되었습니다. 이 모델은 다양한 NLP 데이터셋의 멀티태스크 혼합 데이터를 사용하여 학습되었습니다.
ERNIE 3.0: [81] Sun 등은 대규모 지식 강화 모델을 사전 학습하기 위한 통합 프레임워크 ERNIE 3.0을 제안했습니다. 이 모델은 자기회귀 네트워크(auto-regressive network)와 자기인코딩 네트워크(auto-encoding network)를 결합하여, 학습된 모델이 제로샷 학습, 소수샷 학습, 또는 미세 조정을 통해 자연어 이해와 생성 작업 모두에 쉽게 적응할 수 있도록 설계되었습니다. ERNIE 3.0은 10억 개의 매개변수를 사용해 평문 텍스트와 대규모 지식 그래프로 구성된 4TB 코퍼스에서 학습되었습니다. 모델 아키텍처는 그림 17에 나타나 있습니다.
RETRO: [82] Borgeaud 등은 RETRO(Retrieval-Enhanced Transformer)라는 모델을 통해 문서 조각을 활용하여 언어 모델 성능을 향상시켰습니다. 이 모델은 이전 토큰과의 지역적 유사성을 기반으로 대규모 코퍼스에서 문서 조각을 검색하여 조건부 학습을 수행합니다. 2조 개의 토큰 데이터베이스를 사용해 학습된 Retro는 GPT-3 및 Jurassic-1 [83]과 유사한 성능을 보이면서도 25% 적은 매개변수를 사용했습니다. 그림 18에서 Retro는 고정된 BERT 검색기, 차별화 가능한 인코더, 조각화된 교차 주의 메커니즘을 결합하여 일반적인 학습 중 소비되는 데이터 양보다 훨씬 많은 데이터를 기반으로 토큰을 예측하는 방식을 보여줍니다.
GLaM: [84] Du 등은 GLaM(Generalist Language Model)이라는 대규모 언어 모델 패밀리를 제안했습니다. 이 모델은 희소 활성화 전문가 혼합(Mixture-of-Experts) 아키텍처를 사용하여 모델 용량을 확장하면서도 밀집 모델(dense model)에 비해 학습 비용을 크게 줄였습니다. 가장 큰 GLaM 모델은 1.2조 개의 매개변수를 가지며, 이는 GPT-3보다 약 7배 더 크지만 학습 시 사용된 에너지는 1/3에 불과하고 추론 시 필요한 계산량도 절반으로 줄였습니다. 그럼에도 불구하고 29개의 NLP 작업에서 제로샷, 원샷, 소수샷 성능이 더 뛰어납니다. GLaM의 상위 아키텍처는 그림 19에 나와 있습니다.
LaMDA: [85] Thoppilan 등은 LaMDA(Language Model for Dialog Applications)를 소개했습니다. 이 모델은 대화에 특화된 Transformer 기반 신경망 언어 모델로, 최대 137B 매개변수를 가지며 1.56조 단어의 공개 대화 데이터와 웹 텍스트에서 사전 학습되었습니다. 주석 데이터를 사용한 미세 조정 및 외부 지식 소스 활용을 통해 안전성과 사실 기반 강화라는 두 가지 주요 문제를 크게 개선할 수 있음을 보여주었습니다.
OPT: [86] Zhang 등은 OPT(Open Pre-trained Transformers)라는 125M에서 175B 매개변수에 이르는 디코더 전용 사전 학습 Transformer 모델들을 연구자들에게 공개했습니다. OPT 모델의 매개변수는 그림 20에 나타나 있습니다.
Chinchilla: [2] Hoffmann 등은 Transformer 언어 모델을 주어진 계산 예산 내에서 학습할 때 최적의 모델 크기와 학습 토큰 수를 연구했습니다. 70M에서 16B 이상의 매개변수를 가진 400개의 언어 모델을 50억에서 500억 개의 토큰으로 학습한 결과, 계산 최적화를 위해 모델 크기와 학습 토큰 수를 동일하게 확장해야 한다는 결론을 내렸습니다. 즉, 모델 크기가 두 배가 되면 학습 토큰 수도 두 배가 되어야 합니다. 이 가설을 바탕으로 Gopher와 동일한 계산 예산으로 Chinchilla라는 70B 매개변수 모델을 학습시켰고, 4% 더 많은 데이터를 사용했습니다.
Galactica: [87] Taylor 등은 과학적 지식을 저장, 결합 및 추론할 수 있는 대규모 언어 모델인 Galactica를 소개했습니다. 이 모델은 논문, 참조 자료, 지식 기반 등 다양한 과학 데이터로 학습되었습니다. Galactica는 수리적 MMLU에서 Chinchilla를 41.3% 대 35.7%로, MATH에서 PaLM 540B를 20.4% 대 8.8%로 능가하며 뛰어난 성과를 보였습니다.
CodeGen: [88] Nijkamp 등은 자연어 및 프로그래밍 언어 데이터를 기반으로 최대 16.1B 매개변수를 가진 CodeGen 모델 패밀리를 학습하고, JAXFORMER라는 학습 라이브러리를 오픈소스로 공개했습니다. 이들은 CodeGen이 HumanEval에서 파이썬 코드 생성의 제로샷 작업에서 이전 최신 모델과 경쟁할 수 있음을 보여주었습니다. 또한 단일 프로그램을 하위 문제를 명시하는 여러 프롬프트로 분할하는 다단계 프로그램 합성 패러다임을 조사했습니다. 이들은 115개의 다양한 문제 세트로 구성된 다중 회차 프로그래밍 벤치마크(MTPB)를 구축해 이를 평가에 활용했습니다.
AlexaTM: [89] Soltan 등은 혼합 디노이징(denoising)과 인과적 언어 모델링(Causal Language Modeling, CLM) 작업으로 사전 학습된 대규모 다국어 시퀀스-투-시퀀스(seq2seq) 모델이 다양한 작업에서 디코더 전용 모델보다 더 효율적인 소수 샷 학습자임을 입증했습니다. 이들은 200억 매개변수를 가진 다국어 seq2seq 모델인 Alexa Teacher Model(AlexaTM 20B)을 학습시켜, 1샷 요약 작업에서 5400억 매개변수의 PaLM 디코더 모델을 능가하는 성능을 보여주었습니다. AlexaTM은 46개의 인코더 레이어, 32개의 디코더 레이어, 32개의 어텐션 헤드, 그리고 dmodel=4096을 포함합니다.
Sparrow: [90] Glaese 등은 Sparrow라는 정보 검색 대화 에이전트를 발표했습니다. 이 모델은 기존의 프롬프트 기반 언어 모델에 비해 더 도움이 되고, 정확하며, 무해하도록 훈련되었습니다. 이들은 인간 피드백을 기반으로 강화 학습을 사용하여 모델을 학습시켰으며, 인간 평가자가 에이전트 행동을 판단하도록 돕기 위한 두 가지 새로운 요소를 추가했습니다. Sparrow 모델의 고수준 파이프라인은 그림 21에 나와 있습니다.
Minerva: [91] Lewkowycz 등은 Minerva를 소개했습니다. 이 모델은 일반 자연어 데이터를 사전 학습한 후 기술 콘텐츠로 추가 학습되어 수학, 과학, 공학 문제를 해결하는 등 정량적 추론에 강점을 가진 대규모 언어 모델입니다.
MoD: [92] Tay 등은 NLP에서 자기 지도 학습에 대한 일반화되고 통합된 관점을 제안하며, 다양한 사전 학습 목표를 상호 변환할 수 있고 이를 조합하면 효과적일 수 있음을 보였습니다. 이들은 다양한 사전 학습 패러다임을 결합한 사전 학습 목표인 Mixture-of-Denoisers(MoD)를 제안했습니다. 이 프레임워크는 UL2(Unifying Language Learning)로 알려져 있으며, UL2 사전 학습 패러다임의 개요는 그림 21에 나와 있습니다.
BLOOM: [93] Scao 등은 BLOOM이라는 176B 매개변수의 오픈 액세스 언어 모델을 발표했습니다. 이 모델은 46개의 자연어와 13개의 프로그래밍 언어(총 59개)로 구성된 ROOTS 코퍼스를 사용해 학습되었으며, 수백 명의 연구자들이 협업하여 설계 및 구축했습니다. BLOOM 아키텍처의 개요는 그림 23에 나와 있습니다.
GLM: [94] Zeng 등은 130B 매개변수를 가진 GLM-130B를 소개했습니다. 이 모델은 영어와 중국어를 지원하는 양방향 사전 학습 언어 모델로, GPT-3(davinci)와 동등한 수준의 성능을 가진 100B 규모의 모델을 오픈소스화하려는 시도의 일환이었습니다.
Pythia: [95] Biderman 등은 Pythia라는 16개의 대규모 언어 모델 세트를 소개했습니다. 이 모델들은 모두 동일한 순서의 공개 데이터를 사용해 학습되었으며, 70M에서 12B 매개변수까지 다양합니다. 각 모델에 대해 154개의 체크포인트와 정확한 데이터 로더를 재구성할 수 있는 도구를 공개했습니다.
Orca: [96] Mukherjee 등은 Orca라는 130억 매개변수 모델을 개발했습니다. 이 모델은 대규모 기본 모델의 추론 과정을 모방하도록 설계되었습니다. Orca는 GPT-4의 풍부한 신호(설명 추적, 단계별 사고 과정, 복잡한 명령 등)를 활용해 학습되었으며, ChatGPT의 교사 지원을 받아 개발되었습니다.
StarCoder: [97] Li 등은 StarCoder와 StarCoderBase를 소개했습니다. 이 모델들은 155억 매개변수와 8K 문맥 길이를 가지며, 멀티쿼리 어텐션을 통해 대규모 배치 추론 속도가 향상되었습니다. StarCoderBase는 GitHub의 허용된 라이선스 리포지토리 모음인 The Stack에서 얻은 1조 토큰으로 학습되었으며, 350억 Python 토큰으로 미세 조정되어 StarCoder가 생성되었습니다. 이들은 다양한 프로그래밍 언어를 지원하는 공개 코드 LLM 중 가장 포괄적인 평가를 수행했으며, StarCoderBase가 OpenAI의 code-cushman-001 모델과 동등하거나 더 나은 성능을 보였음을 입증했습니다.
KOSMOS: [98] Huang 등은 KOSMOS-1을 소개했습니다. 이 모델은 멀티모달 대규모 언어 모델(MLLM)로, 일반적인 모달리티를 인식하고(예: 소수 샷 학습), 명령을 따를 수 있습니다(예: 제로 샷). 이들은 웹 규모 멀티모달 코퍼스(텍스트와 이미지, 이미지-캡션 쌍, 텍스트 데이터를 포함)를 사용해 KOSMOS-1을 처음부터 학습시켰습니다. 실험 결과, KOSMOS-1은 (i) 언어 이해, 생성, OCR 없는 NLP(문서 이미지를 직접 입력), (ii) 멀티모달 대화, 이미지 캡션 생성, 시각적 질문 응답, (iii) 이미지 설명을 통한 인식(텍스트 명령으로 분류 지정) 작업에서 우수한 성능을 보였습니다.
Gemini: [99] Gemini 팀은 이미지, 오디오, 비디오, 텍스트 이해를 모두 지원하는 새로운 멀티모달 모델 패밀리 Gemini를 소개했습니다. Gemini는 고난도 작업을 위한 Ultra, 확장 가능한 성능과 배포 가능성을 위한 Pro, 장치 내 애플리케이션을 위한 Nano로 구성됩니다. Gemini 아키텍처는 Transformer 디코더를 기반으로 하며, 효율적인 어텐션 메커니즘을 통해 32k 문맥 길이를 지원하도록 학습되었습니다.
기타 LLM 프레임워크 및 기술: 기타 인기 있는 LLM 프레임워크 및 효율적인 LLM 개발 기술에는 InnerMonologue [100], Megatron-Turing NLG [101], LongFormer [102], OPT-IML [103], MeTaLM [104], Dromedary [105], Palmyra [106], Camel [107], Yalm [108], MPT [109], ORCA2 [110], Gorilla [67], PAL [111], Claude [112], CodeGen 2 [113], Zephyr [114], Grok [115], Qwen [116], Mamba [30], Mixtral-8x7B [117], DocLLM [118], DeepSeek-Coder [119], FuseLLM-7B [120], TinyLlama-1.1B [121], LLaMA-Pro-8B [122] 등이 포함됩니다.
그림 24는 대표적인 LLM 프레임워크의 개요와 LLM 발전에 기여하며 한계를 확장한 관련 연구를 보여줍니다.
'논문 리뷰 > Survey 논문' 카테고리의 다른 글
| A Survey of Confidence Estimation and Calibrationin Large Language Models (0) | 2025.01.17 |
|---|---|
| [4/4] Large Language Models: A Survey (0) | 2025.01.16 |
| [2/4] Large Language Models: A Survey (0) | 2025.01.15 |
| The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey (1) | 2024.12.26 |


